Regular Expression is a set of characters that defines a search pattern in a text. Regular Expression is used in UNIX text processing utilities like AWK, sed, grep, and more. It was first formalized by mathematician Stephen Cole Kleene in the 1950s.
In regex, we have two categories of characters.
- Regular (Literal) characters: Literally any character as we use it in the English language.
- Meta characters: These characters can be either special characters like $ or ^ and so on, or can be literal characters with a backslash in front of them like \d or \w. These characters carry a special meaning, for example, \d matches a single digit in a text or ^ matches the beginning of a string.
Regular Expressions are not specific to Linux or any programming language and what is supported depends on the tool you use. In this tutorial, we will cover Regular Expressions that can be used in a UNIX environment.
First, let's get introduced to different categories of Regular Expressions and what they can do with simple examples. Then, we will see how to use them together to match complex patterns.
Most applications support regex search and here I am using VSCode search box with regex activated (.*). Later in this tutorial, you will see a few examples of using regex with grep as well.
The most basic regex pattern
A single literal character or a set of characters without using any meta characters is the basic search pattern in regex. For example, when you search for the word "the" in a text file, the regex matches the letter "t" followed by "h" followed by "e" anywhere in that text.
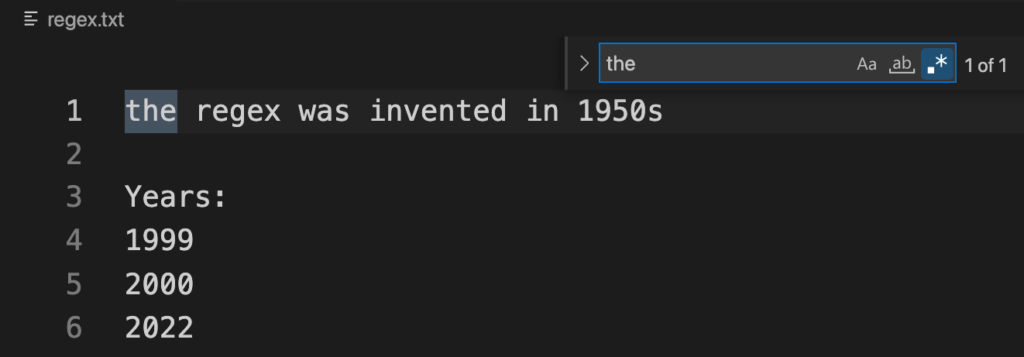
Single Characters
| \d | Matches any digit 0-9 in a text |
| \w | Matches all ASCII characters, digits, and underscore. |
| \W | This is the opposite of \w. It matches anything but a word. |
| \s | Matches any whitespace. |
| \S | Matches anything but whitespaces. |
| \t | Matches tabs. |
| \ | Escapes a special character. |
| . | Any character except line break |
For example, used \d to match any single digit.
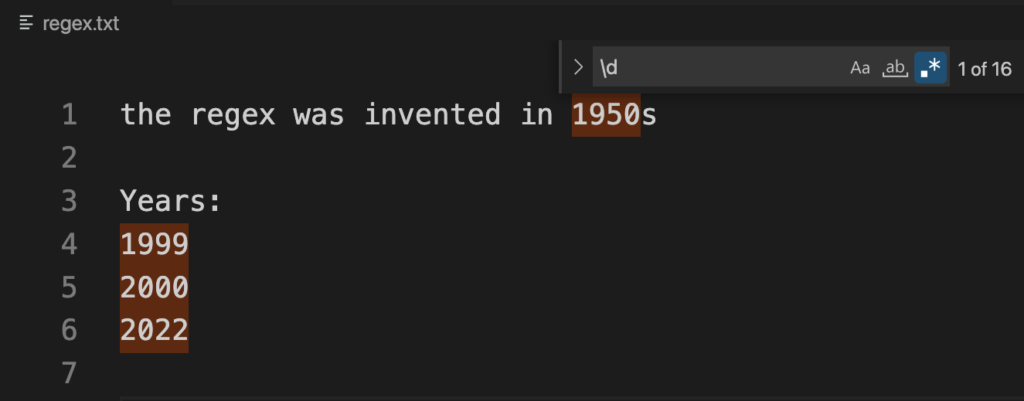
Quantifiers
Quantifiers are metacharacters that find repeated patterns. For example, to find the 4-digit numbers, instead of using \d\d\d\d we can use \d{4} (any digit times four), and that will return any four-digit number like 2022.
| * | Matches the preceding character 0 or more times. |
| + | Matches the preceding character 1 or more times. |
| {n} | Matches the preceding character n times. |
| {n,m} | Matches the preceding character minimum n and maximum m times |
| {n,} | Matches the preceding character n or more times. |
| ? | Matches the preceding character 0 or 1 time. |
For example, find any 4-digit number in the regex.txt file.
RegEx: \d{4}
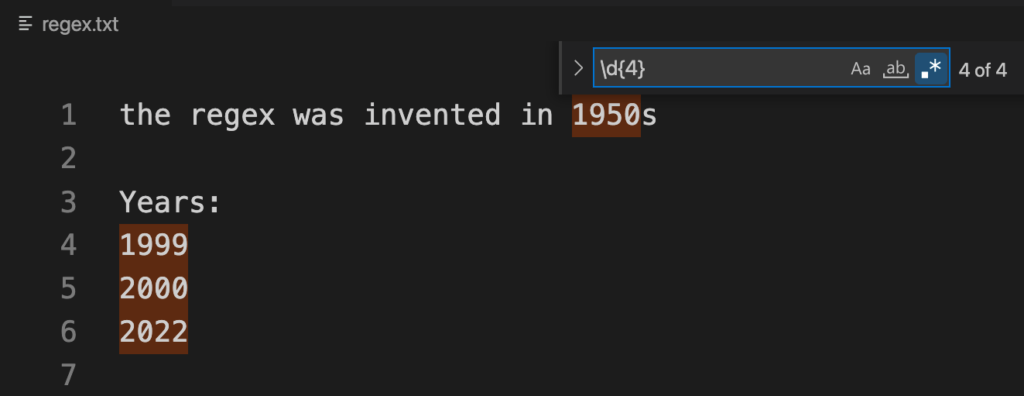
Explanation: \d represents a single digit and {4} multiplies it 4 times, thus 4 digit numbers are matched.
Alternation
Alternation is the logical OR operand in regex. Like in many programming languages, It's represented with the | symbol in regex. It takes two or more regular expressions and matches any of them in a text.
For example, find 1999 or 2000 in regex.txt

Both sides of the OR operand are two separate regexes.
Character Classes
Character class or Character Set is represented by square brackets [ ] in regex and it matches any single character inside the square brackets. For example, find all the lines that start with a vowel.
Regex: ^[aieou]
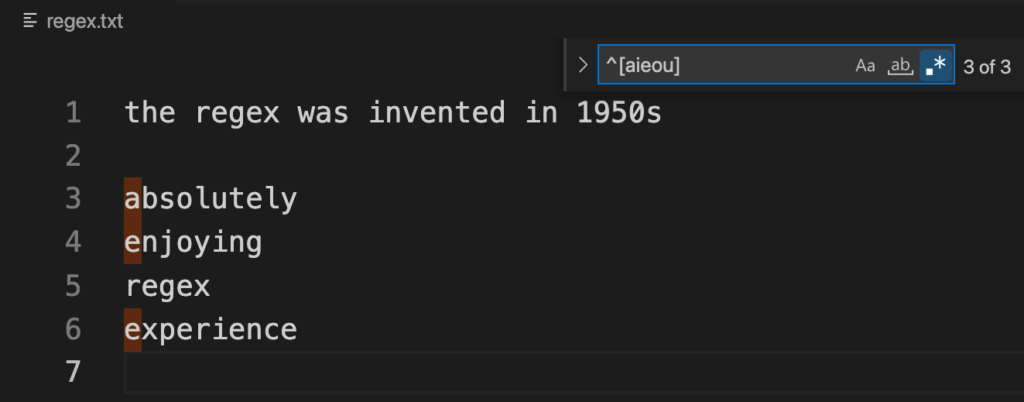
Explanation: As we know, the Caret ^ matches any line that begins with the characters coming after it, and [aieou] means that the character can be any of the characters within the character class.
A dash (-) inside a character class is treated as a special character if it is not the first or last item. A dash specifies a range within a character class. For example, [A-Z] matches any capital letter from A to Z, or [0-9] matches any single digit. If the dash is the first item inside the character class, it's treated as a literal character.

In addition, a caret (^) is a special character inside a character class if it is the first item. It negates the character class in this case. For example, [^A-Z] matches anything BUT the capital letters A to Z.
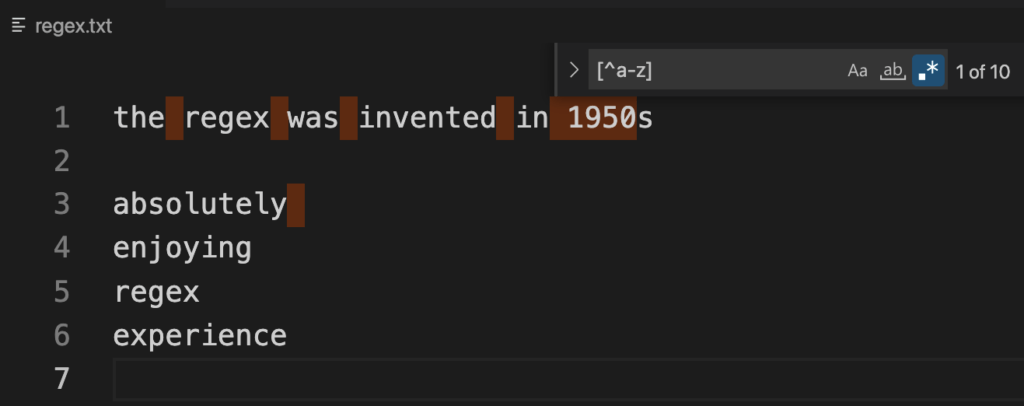
Moreover, a dot (.) is treated as a literal character inside a character class. Otherwise, a dot matches anything except a line break.
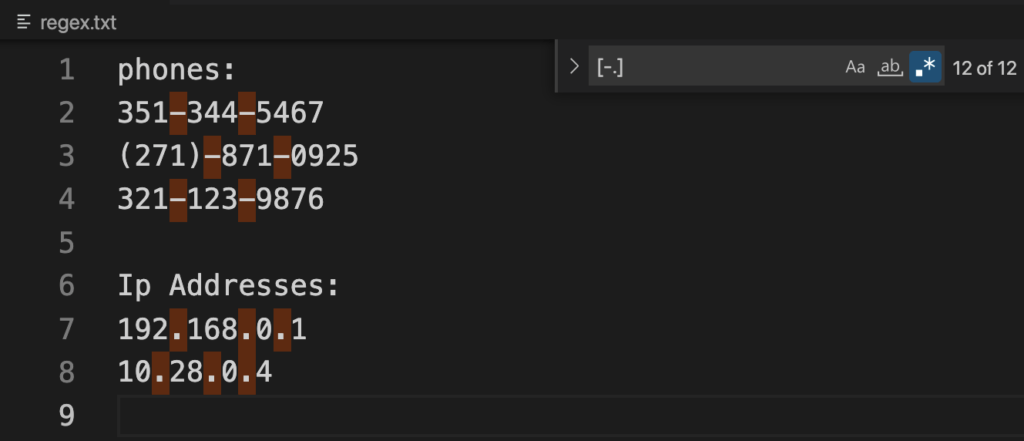
For example, [-.] matches either a dash or a dot.
Grouping, Capturing, and Backreferencing
Using parenthesis, we can group multiple characters into a single unit. The result from the groups will be stored in the memory for reference. We can refer to the first group with $1, the second group $2, and so on.
For example, imagine replacing the last two octets of an IP address like changing 192.168.1.2 to 192.168.0.0
Regex: (\d{1,3}.\d{1,3}).\d{1,3}.\d{1,3}

Replacing the last two octets of an IP address with zeros
When using a group result outside of a regex, we use the dollar sign $. However, referencing a group inside the regular expression itself is done with a backslash (\) like \1 to refer to the first group. This is called Backreferencing.
Example: Find duplicate words like "is is"
Regex: (\w+)\s\1
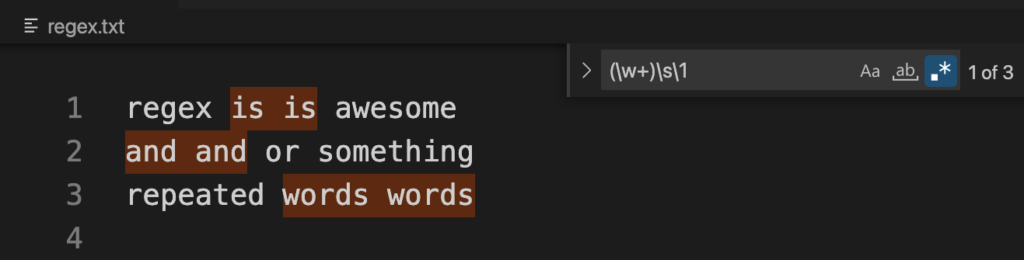
Explanation:
The \w+ matches any word character 1 or more times and we capture that in a group. Next, \s matches a whitespace, and finally \1 refers back to the group we captured, that is the first word.
To ignore capturing but still use grouping in regex, use (?:x) format. This is a good practice if capturing and backreferences are not going to be used.
Some Examples
Example 1: Find email addresses
I have the following emails in regex.txt, let's assume we want to match all email addresses using grep.
emails:
john@example.com
rick@example.net
mark@example.io
bob.logan@something.comThe following Regex will match these emails in a simple format.
\w+\.?\w+@\w+(?:\.com|\.net|\.io)Explanation:
The \w+ matches 1 or more word characters.
The \.? matches an optional dot between two words
The second \w+ matches the last name if provided
The @ symbol is just a literal character
The (?:.com|.net|.io) is a group (without capturing) and is using OR operand to match top-level domains.
In this example, I am using this regex with grep:
grep -E '\w+\.?\w+@\w+(?:\.com|\.net|\.io)' regex.txtOutput:

The -E option enables Extended Regular Expressions for grep as standalone grep only supports Basic Regular Expression which has limited special characters. You can find more about how to use grep in this article.
Example 2: Match phone numbers
I have the following lines in my file regex.txt
phones:
351-344-5467
(271)-871-0925To match both formats, the following RegEX can be used:
\(?\d{3}\)?[-.]\d{3}[-.]\d{4}Explanation:
The \(? matches an optional opening parenthesis (a literal character as it's escaped by the backslash).
\d{3 matches a 3-digit number.
\)? matches an optional closing parenthesis.
[-.] the next character can be either a dash (-) or a dot (.).
\d{3} matches the next 3-digit number.
Again, [-.] the next character can be either a dash (-) or a dot (.).
Finally, \d{4} matches the last 4-digit number.
grep -E '\(?\d{3}\)?[-.]\d{3}[-.]\d{4}' regex.txt
Conclusion
The main purpose of using regex is to find patterns in a text. Regular Expression is a huge topic but you don't need to know everything about regex to use them. In this tutorial, we covered the important use cases of regex. You can use regex with Linux utilities such as grep, awk, sed, and more.





