Global Regular Expression Print (grep) is a UNIX utility that searches text files or standard input for lines that match a string (Regular Expression) and prints the result to standard output.
Regular Expressions (regex) is a set of characters that help to effectively match strings in texts or files. Regular Expressions initially included a few characters and it was extended later on to include a few more.
For more information about regex in UNIX/Linux, please visit this article.
The initial set of characters is called Basic Regular Expressions and the extended set of characters, in addition to the initial set of characters, is called Extended Regular Expressions.
Basic Regular Expressions characters support the following:
| . | Match any single character in a string |
| [ ] | Match any character inside the brackets or range of characters and numbers |
| ^ | Matches the first character of a string |
| $ | Matches the last character of a string |
Extended Regular Expressions supports Basic Regular Expressions and some additional characters:
| {n} | Match the preceding characters exactly n times |
| {n,m} | Matches the preceding element at least n and not more than m times |
| ? | Match the preceding characters one or zero times |
| + | Matches the preceding characters one or more times |
| | | Match either of the string choices e.g “abc”|”def” - either “abc” OR “def” |
| * | Match the preceding element zero or more times. |
To skip any of these characters and treat them as string literals, put a backslash in front of them. For example, if you want the ? to not be treated as a regular expression character but just as a question mark, use \?. This is true for all regular expressions.
Grep supports Basic Regular Expression by default and Extended Regular Expression with the -E option. If you prefer, there is a separate command for grep -E, and that is called egrep.
In this tutorial, you will learn how to use grep with strings, Basic Regular Expressions, and Extended Regular Expressions.
grep syntax
grep [options] 'expression' text[options] e.g -ior -E, We are going to explore them in a little bit.
The expression represents a search pattern that can be a string literal or a Regular Expression.
The text represents standard input that can be a file, multiple files, or the output of another command.
I have prepared a list of movies in a file named movies.txt and we will use this text file as an input to grep and search through this file for specific search patterns.
Top movies of all time:
The Shawshank Redemption (1994) - 9.2
The Godfather (1972) - 9.2
The Dark Knight (2008) - 9.0
the godfather part II (1974) - 9.0
Angry Men (1957) - 8.9
City of God (2002) - 8.6Basic search
To see if 'Godfather' is in movies.txt
grep 'Godfather' movies.txt Output

Grep returns the line containing the search term 'Godfather.
Using grep with Regular Expressions
Example 1: Search for movies that have "The" in front of them.
grep '^The' movies.txtOutput:

As we know, the ^ symbol in regex matches the lines starting with the preceding characters.
Example 2: Search for movies that are released after the year 2000:
grep '20[0-9][0-9]' movies.txtOutput:

Movies after 2000 can be represented as 20xx, and each x is any number between 0 to 9, therefore replaced with [0-9] in the expression.
What is egrep?
As mentioned, egrep is another command for grep -E which allows using Extended Regular Expressions. Let's see an example
Find movies that have either the word "Godfather" or "Dark"
We know the OR in Extended Regular Expression is represented by |.
grep -E 'Godfather|Dark' movies.txtOutput

If we use grep alone (without -E option), the above command will return nothing as it treats |symbol as a literal and not a special character.
Also, the above command is equivalent of the following command:
egrep 'Godfather|Dark' movies.txtIgnore case sensitivity
If you noticed in the movies.txt file, we have the movie "the godfather part II" with small letters as well, but none of our searches with the search term "Godfather" returned this line. That is because grep is case sensitive, and we can ignore the case sensitivity using -i option
grep -i 'Godfather' movies.txtOutput

We can see that both lines with the term 'godfather' are returned, regardless of the case.
Search for the full word
Let's see what happens if we search for the word "God"
grep 'God' movies.txtoutput

Both movies with the keywords 'Godfather' and 'God' are matched. That is because both keywords have the letters "God".
To only match 'God' (full word), you can use the -w option
grep -w 'God' movies.txtOutput

Return matched word only
We can use -o option to only return the searched word and not the whole line.
grep -o 'Godfather' movies.txtOutput:

Inverted Search
Inverted search returns everything except the 'expression'. It's the opposite of a normal search.
For example, let's return all the movies with don't have the word 'God'
grep -v 'God' movies.txtOutput

We can see all the movies which do not have the term 'God' in them. However, we still see 'godfather' in there. That is because we did not ignore case sensitivity in our search term. We can use -i option in combination with -v like the following
grep -iv 'God' movies.txtOutput

Return the results with line numbers
Finding the line number can be very useful if you want to edit the line matching the 'expression'
For this, use -n option
grep -n 'Angry Men' movies.txtOutput

There we have it. The term 'Angry Men' appears at line number 7
We can use editors like vim to edit that particular line
vim +7 movies.txtIt will take you directly to line number 7.
Count matching word
If we want to know how many movies have the word 'God', we can use -c option
grep -c 'God' movies.txtOutput

Again, we can combine -c with -i option to know how many movies have either "God" or "god" in their title.
grep -ic 'god' movies.txtOutput

Return exact match (Full line)
To know if a search term (expression) matches a line, use the -x option.
grep -x 'City of God (2002) - 8.6' movies.txtIt will only match if the full line matches the searched term:

Return file names that have the search term
To see which files have our search term (expression), we use -l option. We can pass multiple file names to it or use an asterisk (*).
grep -l 'Godfather' movies.txt grep.shor
grep -l 'Godfather' ./* Here we are telling grep to look for 'Godfather' in any file located in the current directory.
Output:
./grep.sh
./movies.txtUsing -l option alone will only search the current directory, if there are subdirectories in the current directory, grep will not search them and throw an error. That is because grep expects a file. To overcome this, we combine -l with -r option to look for any file recursively.
grep -lr 'Godfather' ./grepThe dot (.) represents the current directory in Linux.
Output:

Return file names and the matching lines
This works like -l option with extra functionality to return what the matching line looks like within the files.
We use the -H option:
grep -Hr 'Godfather' ./grepOutput:

As you can see, the -H option returns the file names along with the matching lines, separated by a colon (:).
Return additional lines after the match
Sometimes we want to know what lines come after the matching line. We can use -A option like below.
To print additional 2 lines after the matching line:
grep -A2 'Dark Knight' movies.txt Output:

So we have not only the line matching the expression "Dark Knight", but we also have the 2 lines coming after that.
Return lines before the match
This is just like -A option, but it works in the opposite direction. We use -B (for before) to achieve this.
To get 2 lines before the line with the matching expression "Dark Knight":
grep -B2 'Dark Knight' movies.txtOutput:

Return lines before and after the match
This combines both -A and -B options. We use -C to achieve this.
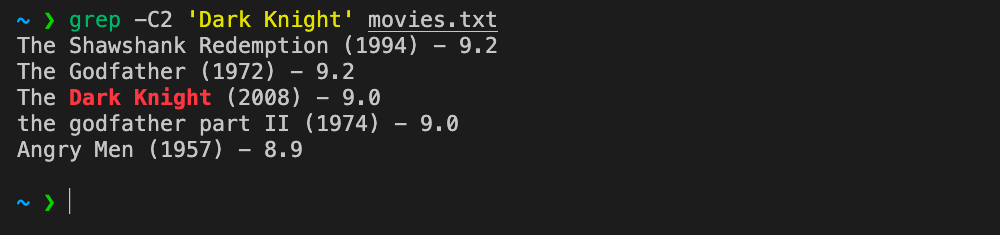
To return 2 lines before and 2 lines after the line with the term "Dark Knight":
grep -C2 'Dark Knight' movies.txtOutput:
Search output of other commands using grep
We can pass the output of any command as standard input to grep using Linux pipes and search it the same way we search files.
For example, let's search the output of ls command.
List only directories:
ls -l | grep '^d'From the Regular Expressions, we know that ^ means match any line in the output that starts with the letter "d", which means a directory in Linux.
Output:

Conclusion
grep is a very powerful and useful command in UNIX systems that if used properly can save us precious time. Using Regular Expression makes it very effective and efficient to search for text patterns in a file, multiple files, directories, and output of other commands. In this tutorial, we explained how to use grep with regular expressions and demonstrated some of the most useful grep options.





